While it is feasible to exploit LDAP authentication and authorization "pervasively" across all nodes upon which the various ControlTier components are installed, what is documented here is the more modest design goal of using LDAP to secure access only to the centralized ControlTier server conventionally deployed to provide a single point of administration in the network.
This is a practical compromise when you consider that more often than not, command execution on remote client systems is tied to one or more system level "application" accounts as opposed to individual user's logins. These accounts are used to construct the network of public key based passwordless secure shell access from the ControlTier server.
Comprehensive authentication and authorization for ControlTier is therefore achieved at two levels:
- At the system level, login access to the server and client systems must be restricted to the set of individuals authorized to use the ControlTier and "application" accounts that provide unfettered access to executing build and deployment commands in the distributed infrastructure.
- At the project level, access to the Workbench model, and Jobcenter command interface must be filtered by the user and role-based authentication and authorization scheme intrinsic to those applications.
It is in the latter case that this posting covers using LDAP to manage levels of access to ControlTier's web based services.
Deploying an LDAP instanceYou can skip this section if you have an LDAP server available on your network that is accessible from the ControlTier server.
Assuming such a service does not already exist, the first step is to setup an LDAP server instance on a system that is accessible to the ControlTier server. There are many LDAP server implementations available, but here's how to setup the most popular Open Source version:
OpenLDAP.
The OpenLDAP
Quick Start Guide proposes building the officially released software from source. There are a number of
binary distributions available on the Internet, of course, and many Unix variant OSes package OpenLDAP with their releases.
In this case, I used a CentOS 4.5 instance.
These instructions assume you wish to configure and deploy a non-superuser based LDAP server instance to support ControlTier:
- Acquire, or build OpenLDAP from source. In this case, the software is built from source and installed under $CTIER_ROOT/pkgs to facilitate executing as the ControlTier server account (e.g. "ctier"):
$ cd $CTIER_ROOT/src
$ tar zxf openldap-2.4.8.tgz
$ cd openldap-2.4.8
$ ./configure --prefix=$CTIER_ROOT/pkgs/openldap-2.4.8
Configuring OpenLDAP 2.4.8-Release ...
checking build system type... i686-pc-linux-gnu
checking host system type... i686-pc-linux-gnu
checking target system type... i686-pc-linux-gnu
.
.
.
Making servers/slapd/overlays/statover.c
Add seqmod ...
Add syncprov ...
Please run "make depend" to build dependencies
$ make depend
.
.
.
$ make
.
.
.
$ make install
.
.
.
$ file $CTIER_ROOT/pkgs/openldap-2.4.8/libexec/slapd
.../slapd: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), for GNU/Linux 2.2.5, dynamically linked (uses shared libs), stripped
- Customize the "slapd.conf" configuration file (in this case using the "controltier.com" domain):
$ cd $CTIER_ROOT/pkgs/openldap-2.4.8/etc/openldap
$ diff slapd.conf slapd.conf.orig
54,55c54,55
< suffix "dc=controltier,dc=com"
< rootdn "cn=Manager,dc=controltier,dc=com"
---
> suffix "dc=my-domain,dc=com"
> rootdn "cn=Manager,dc=my-domain,dc=com"
- Check that the server is up and running:
$ $CTIER_ROOT/pkgs/openldap-2.4.8/bin/ldapsearch -h localhost -p 3890 -x -b '' -s base '(objectclass=*)' namingContexts
# extended LDIF
#
# LDAPv3
# base <> with scope baseObject
# filter: (objectclass=*)
# requesting: namingContexts
#
#
dn:
namingContexts: dc=controltier,dc=com
# search result
search: 2
result: 0 Success
# numResponses: 2
# numEntries: 1
One thing to note is that the Elements module library contains an
OpenLDAP module that can be used to facilitate management of the LDAP instance. Here's sample project object XML to configure a OpenLDAP instance for use with the setup described above:
<project>
<deployment type="OpenLDAP" name="openLDAP" description="Sample Open LDAP service object" installRoot="${env.CTIER_ROOT}/pkgs/openldap-2.4.8" basedir="${env.CTIER_ROOT}/pkgs/openldap-2.4.8" startuprank="1">
<referrers replace="false">
<resource type="Node" name="localhost"/>
</referrers>
</deployment>
</project>
... and sample command output:
$ ad -p TestProject -t OpenLDAP -o openLDAP -c Stop
running command: assertServiceIsDown
Running handler command: stopService
stopService: openLDAP OpenLDAP on localhost stopped.
[command.timer.OpenLDAP.stopService: 0.565 sec]
true. Execution time: 0.565 sec
[command.timer.Service.Stop: 2.998 sec]
command completed successfully. Execution time: 2.998 sec
$ ad -p TestProject -t OpenLDAP -o openLDAP -c Start
running command: assertServiceIsUp
Running handler command: startService
startService: openLDAP OpenLDAP on localhost started.
[command.timer.OpenLDAP.startService: 0.146 sec]
true. Execution time: 0.146 sec
[command.timer.Service.Start: 2.185 sec]
command completed successfully. Execution time: 2.185 sec
$ ad -p TestProject -t OpenLDAP -o openLDAP -c Status
running assertServiceIsUp command
assertServiceIsUp: /proc/4842 found. openLDAP OpenLDAP on localhost is up.
[command.timer.Service.Status: 2.017 sec]
command completed successfully. Execution time: 2.017 sec
Note that this sample configuration is not particularly sophisticated. There are much more flexible (and secure) ways to deploy OpenLDAP documented on their site.
Populating the directoryWorkbench's use of LDAP is pretty straightforward. The Open ControlTier site documents the capabilities of three roles that must exist in the directory:
user - readonly access
admin - can create object
architect - can create objects and create types
Note that both administration and architect users should also be assigned the user role since some elements of the UI assume this (e.g. checks for user role membership are embedded in some of the JSPs).
Note also, that only users with assigned both the admin and architect roles can create new projects.
Please ignore the
sample LDIF file on Open.ControlTier, and use the following file as a guideline to structuring your directory:
$ cat users.ldif
# Define top-level entry:
dn: dc=controltier,dc=com
objectClass: dcObject
objectClass: organization
o: ControlTier, Inc.
dc: controltier
# Define an entry to contain users:
dn: ou=users,dc=controltier,dc=com
objectClass: organizationalUnit
ou: users
# Define some users:
dn: cn=user1, ou=users,dc=controltier,dc=com
userPassword: password
objectClass: person
sn: A user account with simple user privileges
cn: user1
dn: cn=user2, ou=users,dc=controltier,dc=com
userPassword: password
objectClass: person
sn: A user account with user and administrator privileges
cn: user2
dn: cn=user3, ou=users,dc=controltier,dc=com
userPassword: password
objectClass: person
sn: A user account with user, administrator and architect privileges
cn: user3
dn: cn=default, ou=users,dc=controltier,dc=com
userPassword: default
objectClass: person
sn: The default account for the ControlTier client to use
cn: default
dn: ou=roles, dc=controltier,dc=com
objectClass: organizationalUnit
ou: roles
dn: cn=architect, ou=roles,dc=controltier,dc=com
objectClass: groupOfUniqueNames
uniqueMember: cn=user3,ou=users,dc=controltier,dc=com
cn: architect
dn: cn=admin, ou=roles,dc=controltier,dc=com
objectClass: groupOfUniqueNames
uniqueMember: cn=user2,ou=users,dc=controltier,dc=com
uniqueMember: cn=user3,ou=users,dc=controltier,dc=com
uniqueMember: cn=default,ou=users,dc=controltier,dc=com
cn: admin
dn: cn=user, ou=roles,dc=controltier,dc=com
objectClass: groupOfUniqueNames
uniqueMember: cn=user1,ou=users,dc=controltier,dc=com
uniqueMember: cn=user2,ou=users,dc=controltier,dc=com
uniqueMember: cn=user3,ou=users,dc=controltier,dc=com
cn: user
Here's the command used to load the records into OpenLDAP:
$ ldapadd -x -H ldap://localhost:3890/ -D "cn=Manager,dc=controltier,dc=com" -w secret -f users.ldif
You can see that it is important to use OS access controls to safeguard the contents of this file from unauthorized access.
Note that you can supplement OpenLDAP's command line interface with
JXplorer, an Open Source Java LDAP browser/editor client application.
Configuring Workbench to use LDAP
The next piece of the puzzle is to adjust Tomcat's security "Realm" configuration to use the LDAP server. All that's necessary is to replace the default "UserDatabaseRealm" element in "server.xml" with the following "JNDIRealm" setup:
<Realm className="org.apache.catalina.realm.JNDIRealm" debug="99"
connectionURL="ldap://localhost:3890/"
roleBase="ou=roles,dc=controltier,dc=com"
roleName="cn"
roleSearch="uniqueMember={0}"
userPattern="cn={0},ou=users,dc=controltier,dc=com"/>
This configuration specifies the connection URL to the LDAP server, matches the role base and user pattern to the repository structure (you may need to adjust these for your own repository), and uses the "bind method" of authentication described in the Tomcat 4
documentation.
Before restarting Tomcat, a final piece of configuration will make Workbench user management available from the Administration page. Edit the "auth.properties" file to switch from "default" to "jndi" authentication and authorization:
$ cat $CATALINA_BASE/webapps/itnav/WEB-INF/classes/auth.properties
######################################
# auth.properties
# This is the configuration properties file for the User Management feature.
####
# ngps.workbench.auth.type=default
ngps.workbench.auth.type=jndi
######################################
# To enable User Management with JDNI authorization, set the value of ngps.workbench.auth.type to jndi
# then fill in the JNDI configuration below.
######################################
# Configuration for JNDI authorization:
####
ngps.workbench.auth.jndi.connectionName=cn=Manager,dc=controltier,dc=com
ngps.workbench.auth.jndi.connectionPassword=secret
ngps.workbench.auth.jndi.connectionUrl=ldap://localhost:3890/
ngps.workbench.auth.jndi.roleBase=ou=roles,dc=controltier,dc=com
ngps.workbench.auth.jndi.roleNameRDN=cn
ngps.workbench.auth.jndi.roleMemberRDN=uniqueMember
ngps.workbench.auth.jndi.userBase=ou=users,dc=controltier,dc=com
ngps.workbench.auth.jndi.userNameRDN=cn
(Note that with an embedded password this is another file to safeguard with OS access control).
Once JNDI user management is enabled, it is possible to use Workbench user administration to restrict access to individual projects on a user by user basis as well as adjust each user's role assignments:
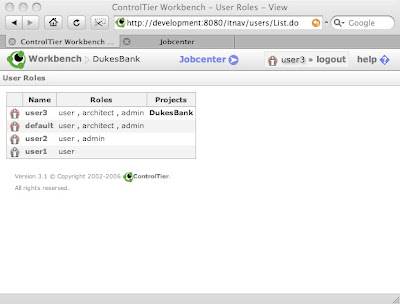 Configuring WebDAV to use LDAP
Configuring WebDAV to use LDAPSince the ControlTier WebDAV repository is deployed to the same Tomcat instance as Workbench it shares the same authentication realm. Not only is it prudent to protect the WebDAV from general browser based access (e.g. by limiting which users can modify the repository), but, just as importantly, the Antdepo client requires access to the repository to upload packages and download packages and modules.
Tomcat 4.1 includes the Apache Slide WebDAV implementation. Slide security is documented in some detail
here. Fine grained access control can be configured both to individual resources and methods. However, from ControlTier's perspective, establishing basic authorization for "admin" role members by adding the following entries to "$CATALINA_BASE/webapps/webdav/WEB-INF/web/xml" and restarting Tomcat is sufficient:
<security-constraint>
<web-resource-collection>
<web-resource-name>Administrative</web-resource-name>
<url-pattern>/*</url-pattern>
</web-resource-collection>
<auth-constraint>
<role-name>admin</role-name>
</auth-constraint>
</security-constraint>
<login-config>
<auth-method>BASIC</auth-method>
<realm-name>JNDIRealm</realm-name>
</login-config>
Note that as of ControlTier 3.1.4, enabling WebDAV authorization and authentication reveals a
bug in the Package module's "upload" command's use of the WebDAV "put" Ant task. The workaround is to fall back to the "scp"-based method of uploading packages to the WebDAV.
Configuring Jobcenter to use LDAPJobcenter LDAP configuration is modeled on Workbench's JNDI provider and implemented as a standard
JAAS LoginModule integrated with Jobcenter's Jetty web application container.
Note: that you
must have installed at least
ControlTier 3.1.4 to follow these Jobcenter configuration instructions!
- Modify $JOBCENTER_HOME/bin/start-jobcenter.sh script to specify "jaas-jndi.conf" in place of "jaas.conf" (this specifies the use of the "org.antdepo.webad.jaas.JNDILoginModule" JAAS login module class instead of the standard "org.antdepo.webad.jaas.PropertyFileLoginModule").
Modify "$JOBCENTER_HOME/webapps/jobcenter/WEB-INF/jaas-jndi.properties". This file has similar configuration properties to the auth.properties used in
workbench for JNDI authentication/authorization. The "connectionPassword", and "connectionUrl" should be modified as necessary. Other properties should be left alone unless the structure of the LDAP directory differs from that setup above:
jobcenter.auth.jndi.connectionName=cn=Manager,dc=controltier,dc=com
jobcenter.auth.jndi.connectionPassword=secret
jobcenter.auth.jndi.connectionUrl=ldap://localhost:3890/
jobcenter.auth.jndi.roleBase=ou=roles,dc=controltier,dc=com
jobcenter.auth.jndi.roleNameRDN=cn
jobcenter.auth.jndi.roleMemberRDN=uniqueMember
jobcenter.auth.jndi.userBase=ou=users,dc=controltier,dc=com
jobcenter.auth.jndi.userNameRDN=cn
The right of a user to execute a job from Jobcenter is synonymous with their underlying Antdepo authorization - Jobcenter literally exploits the Antdepo access control mechanism.
Antdepo access control is based on configuring the "$ANTDEPO_BASE/etc/acls.xml" file. The following DTD and default acls.xml show the scope for customizing authorization levels:
Finally, every Antdepo client installation both local and remote from the ControlTier server requires access to both Workbench and the WebDAV. The sample LDIF above specifies a user called "default" with the password "default" which has the "admin" role. This is the client framework account specified in "$ANTDEPO_BASE/etc/framework.properties":
Naturally you are at liberty (and it is probably advisable) to change this account name and password (they are specified at installation time in "defaults.properties). You should the protect the "framework.properties" file using OS authorization mechanisms.









{kind=link}